

Validation of Chain-of-Thought prompt structuring to improve a language model’s capability to extract new clinical concepts from clinical text messages
2 Department of Biomedical Informatics, Biostatistics, and Medical Epidemiology, School of Medicine, University of Missouri, Columbia, MO, USA
MF: https://orcid.org/0000-0003-0989-2968
KP: https://orcid.org/0000-0002-6144-1438
MP: https://orcid.org/0000-0002-6145-8096
Abstract
The rapid improvement in generative language model capabilities and adoption has increased interest in their application for healthcare, particularly in extracting meaningful information and language from unstructured text. This study investigates the validity of Chain-of-Thought (CoT) prompting on a small language model’s ability to extract clinical concepts from nursing home staff text messages. We focus on concepts within the Age-Friendly Health Systems 4M framework (What Matters, Medication, Mentation, and Mobility). We evaluated the classification performance of four locally-run language models on an expert-annotated dataset of 860 text messages, using classification metrics to compare with or without CoT prompting. Our results demonstrate that CoT prompting improves the capabilities of Gemma 2 9b in extracting expressions related to the 4M framework. However, there was not an improvement observed in the Medication concept. CoT continues to demonstrate potential in improving language model capabilities in the clinical domain, particularly from unstructured text data. This has implications for ontology development, information retrieval, and clinical decision support. Additional contexts or data sources would improve the generalizability of these findings.
Keywords: age-friendly health systems, computer science, gerontology, natural language processing
Introduction
Prior to the public release of ChatGPT in November 2022, Wei et al. (2022) published their foundational paper demonstrating that the inclusion of intermediate reasoning steps, or chain-of-thought (CoT), significantly improved the capabilities of generative language models in the areas of arithmetic, commonsense, and symbolic reasoning tasks (Wei et al., 2022). This growing field of research is, in part, due to the rapid expansion and improved capabilities of generative language models in multiple domains, prompting individuals to examine the scope and depth of large language model capabilities (AL-Smadi et al., 2022, Loh, 2023, Banerjee et al., 2024, Chakraborty et al., 2024, Sahoo et al., 2024).
The purpose of the following study is to provide validation of CoT prompting on the capabilities of a small language model tasked to extract expressions of clinical concepts from unstructured text messages sent to and by clinicians surrounding transfer events in nursing homes. These clinical concepts are found in the evidence-based Age-Friendly Health Systems framework including the 4M’s; “What Matters”, “Medication”, “Mentation” and “Mobility” (Figure 1: Mate et al. 2021). As part of a larger study (Powell et al., 2023), the authors are analyzing text messages sent by nursing home staff to begin development of an ontology supporting this 4M framework. The difficulty of extracting clinical concepts from unstructured text messages is due to the non-standard usage of terms, vocabulary, and contextual placement of conversational text. Our team tested multiple natural language processing techniques to overcome this barrier, including the use of generative language models. Our aim for this report is to describe the prompting techniques we utilized to achieve improved performance in extracting clinical concepts from our text message dataset compared to our expert-annotated “Gold Standard” dataset.
Methods and Materials
Model selection
A small selection of language models capable of running on a local device were chosen to extract the 4M concepts and compared to an expert annotated “Gold Standard” dataset. Models were compared using classification metrics including accuracy, precision, recall, F1, receiver-operator characteristics area-under-curve (ROC-AUC), and Cohen’s Kappa (κ).
The model with highest “off-the-shelf” capabilities was chosen for additional testing and fine tuning. The models tested included: (1) Gemma 2 9b q4_0; (2) Llama 3.1 8b q4_0; (3) Llama 3.1 8b q8_0; (4) Mistral Nemo 12.2b q4_0; and (5) Gemma 2 2b fp16. Model parameters were standardized across models for consistency using the Langchain python package. For thought generation, temperature was set to 0.5 with 500 max tokens. For extraction, temperature was 0.2, repetition penalty = 1.2, repetition context size = 20, top p = 0.95, top_k = 40, and 250 max tokens. Structured, parsed response parameters were set to temperature = 0.0, repetition penalty = 1.2, repetition context size = 20, top p = 0.95, and 50 max tokens. Initial model evaluation tested the performance of a simple extraction task for each model using a system prompt shown in Figure 1 and a prompt for each of the 4Ms, asking the model to extract the correct terms. After initial model testing, the highest performing model was chosen for testing of additional prompt engineering including CoT, model parameter changes, and fine-tuning. Model extractions were compared to the annotated dataset with classification model metrics including: Precision, Recall, F1-Score, Area-under-Curve (AUC), and Cohen’s Kappa. Bootstrap confidence intervals were calculated on model metric comparisons with 1000 bootstrap interactions per test and alpha = 0.05.
Data source and standard
The data source includes 21,357 text messages sent to and by healthcare workers from 12 nursing homes participating in the Missouri Quality Initiative, a CMS-funded innovation and care coordination project that began in 2012 (Powell et al., 2023). The “Gold Standard” dataset consisted of a sample of 860 text messages extracted from the full 21,209 messages and annotated by two clinical experts familiar with the 4M framework. Sampling was accomplished by randomly choosing 40 transfer events and annotating any messages sent up to two weeks prior to the event for 4M content. Annotations were provided independently, then the annotators aligned any discrepancies through discussion of any differing extractions. Additional details of the sampling and annotation methods have been previously reported (Powell et al., 2023). This sample was utilized to assess the model capabilities.
Chain-of-thought prompting
The initial extraction task included a simple prompt instructing the models to make a list of words or phrases consistent with individual 4M concepts. Context (see Figure 1) was provided to the model as a system prompt briefly describing the conceptual definitions of each 4M.
In our chain-of-thought prompting test, we added an additional task prior to term extraction informing the model to provide an explanation of why any words or phrases belong to the individual 4M concept (Xie, 2024). No changes were made to the other prompts or contextual messages.

Results
Gemma 2 9b (9 billion parameters) (Farabet and Warkentin, 2024), Gemma 2 2b, Llama 3.1 8b (Dubey et al., 2024), and Mistral Nemo 12.2b (Mistral AI, 2024) were chosen for initial testing. Models were utilized on a local device for testing to eliminate the risk of sending personal health information online. Model parameters shared between the models included temperature (randomness) =0.0, top_p = 0.9, top_k = 40, and seed (random state) = 418. Gemma 2 9b was the highest performing model for the initial extraction test compared to other models. Chain-of-thought (CoT) prompting was then added. An example of the output is shown in Figure 2. Classification results, displayed in Table 1, improved significantly in 6 metrics in the What Matters and Mobility domains. No significant improvements were achieved in the Mentation domain.
In the Medication domain, the non-chain-of-thought (NonCoT) prompting approach outperformed the chain-of-thought (CoT) model in key classification metrics, with significant differences observed in precision (NonCoT: 0.704 vs. CoT: 0.650; difference: -0.054, 95% CI: -0.096 to -0.015, p=0.006), F1 score (NonCoT: 0.816 vs. CoT: 0.781; difference: -0.035, 95% CI: -0.066 to -0.005, p=0.020), and Cohen’s Kappa (NonCoT: 0.772 vs. CoT: 0.726; difference: -0.046, 95% CI: -0.086 to -0.007, p=0.016), indicating agreement and balanced performance without CoT’s added reasoning steps. Recall showed no significant difference (CoT: 0.979 vs. NonCoT: 0.972; p=0.758), and AUC was comparable (CoT: 0.937 vs. NonCoT: 0.945; p=0.266), suggesting that for medication-related extractions from clinical text, the simpler NonCoT model maintains high discriminative power without the overhead of CoT.
Overall, both models correctly extracted 3053 of 3440 (88.8%) classifications, when the models disagreed on classification, CoT was correct 44.9% of the time. The strongest significant differences by effect size were found in: What Matters – Recall (CoT better by 0.33), F1 (CoT better by 0.14), AUC (CoT better by 0.12), Cohen’s Kappa (CoT better by 0.12); and Mobility – Recall (CoT better by 0.13).
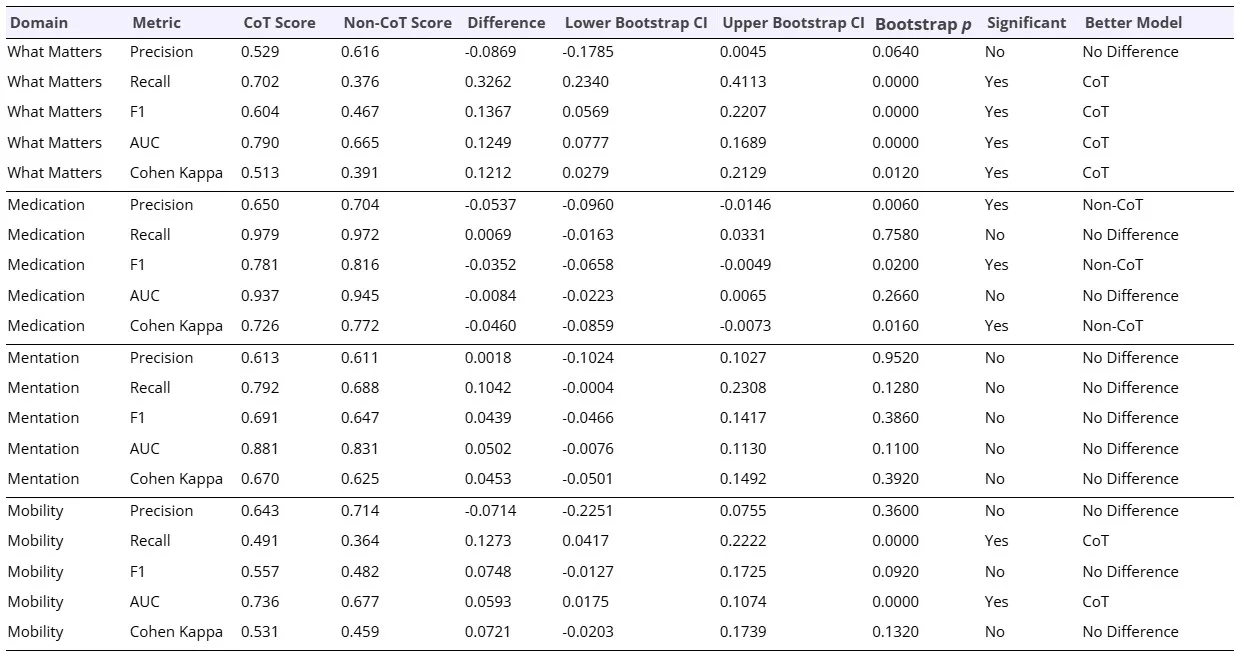
Table 1. Model classification metrics with 95% CI bootstrap significance.
Discussion
Our study demonstrates that chain-of-thought prompting enhances the ability of a small language model, Gemma 2 9b, to extract expressions and 4M clinical concepts from unstructured text messages in the areas of What Matters and Mobility. This finding aligns with previous research by Wei et al., which empirically demonstrated these improvements in their 2022 study (Wei et al., 2022). While CoT improved the performance of extraction in many metrics, the non-CoT model performed significantly better in the medication domain in precision, F1, and Cohen’s Kappa. This suggests that adding a reasoning step may introduce complexity within the Medication concept. In many cases, CoT overanalyzed an extraction where there were no elements to extract. To help illustrate areas where the CoT model misclassified messages, we present 3 cases.
CASE M04251: Non-CoT Correct, CoT Wrong
FULL MESSAGE:
“FYI Upon assessment this morning resident was noted to have periods of increased fatigue and weakness with some unresponsiveness. Irregular heartbeats. Vital signs are as follows: 110/86, 98.1, p89-52, r21, O2@ 91% on RA Assisted to bed and no s/sx of pain or distress noted at this time.”
PREDICTIONS:
-
– Gold Standard: 0 (no medication)
-
– CoT Model: 1 ✗
-
– Non-CoT Model: 0 ✓
EXTRACTED REFERENCES:
-
– Gold Standard: ‘[]’
-
– CoT Extract: ‘[‘vital signs’]’
Model Reasoning: “The text mentions vital signs, which can be indicators of medication effectiveness or side effects.”
-
– Non-CoT Extract: ‘[]’
CASE M04272: Non-CoT Correct, CoT Wrong
FULL MESSAGE:
“TSH results”
PREDICTIONS:
-
– Gold Standard: 0 (no medication)
-
– CoT Model: 1 ✗
-
– Non-CoT Model: 0 ✓
EXTRACTED REFERENCES:
-
– Gold Standard: ‘[]’
-
– CoT Extract: ‘[‘TSH’]’
Model Reasoning: “TSH is a blood test that can indicate thyroid function, which can be relevant to medication management.”
-
– Non-CoT Extract: ‘[]’
CASE M00461: Non-CoT Correct, CoT Wrong
MESSAGE (truncated):
“Wanted to inform you that […] urology office provided a Covid-19 PCR test that was showed that […] was positive for Covid-19. We understand that this was a rapid test. We have isolated…”
PREDICTIONS:
-
– Gold Standard: 0 (no medication)
-
– CoT Model: 1 ✗
-
– Non-CoT Model: 0 ✓
EXTRACTED REFERENCES:
-
– Gold Standard: ‘[]’
-
– CoT Extract: ‘[‘rapid’]”
Model Reasoning: “The text mentions a rapid COVID-19 test, which could be related to medication management as some medications may interact with the virus or affect testing results.”
-
– Non-CoT Extract: ‘[]’

The Gold Standard dataset, limited to annotated text messages, limits the generalizability of our results. Further, our study is focused on a specific set of clinical concepts in the application of text extraction from unstructured text messages. The effect of CoT prompting may vary when applied to other clinical domains or data sources.
Implications for ontology development, information retrieval, and clinical decision support
Our examination of CoT and our ongoing language processing research with the Age-Friendly Health Systems 4M framework (Powell et al., 2023) have provided us with insight into the limitations of language models for ontology development and information retrieval. Despite the improvements of model performance to extract words and phrases from unstructured text using CoT, language models fail to adhere to ontological commitments or align with consensus among subject-matter experts (Neuhaus, 2023). This underscores a key limitation of current generative models in healthcare informatics: their sensitivity to prompt structure for nuanced, context-dependent concepts, rather than rote extraction. However, the relative gains from CoT (e.g., 15-20% improvement in F1 scores for Mobility and What Matters categories, as detailed in Results) are not trivial. The results provide evidence for hybrid approaches in resource-limited environments, such as fine-tuning smaller models combined with structured prompting to approximate expert consensus without extensive retraining. Additional research into the utilization of language models in concept extraction and ontology engineering is ongoing. For clinical decision support systems relying on accurate extractions and categorization of unstructured text in age-friendly health systems, it appears that medication concepts are trained into small language models (without CoT) but more complex concepts such as What Matters and Mobility indicate the need for CoT reasoning.
Author Contributions
Matthew Farmer: Conceptualization, software, resources, formal analysis, investigation, methodology, visualization, writing – original draft
Kimberly Powell: Data curation, resources, supervision, funding, writing – review, project administration
Mihail Popescu: Supervision, writing – review
Data Availability
Due to the personal health information contained in this study, data is not available for review.
Supplemental Information
This study was completed in Python (version 3.12.4) using the following libraries: (1) Pandas (pandas, 2024); (2) json; (3) LangChain (Chase, 2022); and (4) typing. Pydantic (Colvin et al., 2024) classes were utilized to generate structured outputs for use in analysis and additional study.
Transparent Peer Review
Results from the Transparent Peer Review can be found here.
Recommended Citation
Farmer, M., K. Powell, and M. Popescu. 2026. Validation of Chain-of-Thought prompt structuring to improve a language model’s capability to extract new clinical concepts from clinical text messages. Stacks Journal: 26001. https://doi.org/10.60102/stacks-26001
References
AL-Smadi, M. 2023. ChatGPT and beyond: The generative AI revolution in education. arXiv preprint arXiv:2311.15198. https://doi.org/10.48550/arXiv.2311.15198.
Banerjee, S., P. Dunn, S. Conard, and A. Ali. 2024. Mental health applications of generative AI and large language modeling in the United States. International Journal of Environmental Research and Public Health 21: 910. https://doi.org/10.3390/ijerph21070910.
Chakraborty, C., S. Pal, M. Bhattacharya, and A. Islam. 2024. ChatGPT or LLMs can provide treatment suggestions for critical patients with antibiotic-resistant infections: a next-generation revolution for medical science?. International Journal of Surgery 110: 1829-1831. http://dx.doi.org/10.1097/JS9.0000000000000987.
Chase, H. 2022. LangChain (Version 0.1.22). https://github.com/langchain-ai/langchain.
Colvin, S., E. Jolibois, H. Ramezani, A. Garcia Badaracco, T. Dorsey, D. Montague, S. Matveenko, M., Trylesinski, S. Runkle, D. Hewitt, A. Hall, and V. Plot. 2024. Pydantic Validation (Version 2.8.2). https://docs.pydantic.dev/latest/.
Dubey, A., A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, and A. Goyal. 2024. The llama 3 herd of models. arXiv e-prints, pp.arXiv-2407. https://doi.org/10.48550/arXiv.2407.21783.
Farabet, C. and T. Warkentin. 2024. Google launches Gemma 2, its next generation of open models. Accessed September 27, 2024. https://blog.google/technology/developers/google-gemma-2/.
Loh, E. 2023. ChatGPT and generative AI chatbots: challenges and opportunities for science, medicine and medical leaders. BMJ Leader 8: e000797. https://doi.org/10.1136/leader-2023-000797.
Mate, K., T. Fulmer, L. Pelton, A. Berman, A. Bonner, W. Huang, and J. Zhang. 2021. Evidence for the 4Ms: interactions and outcomes across the care continuum. Journal of Aging and Health 33: 469-481. https://doi.org/10.1177/0898264321991658.
Mistral AI. 2024. Mistral NeMo. Accessed September 27, 2024. https://mistral.ai/news/mistral-nemo/.
Neuhaus, F. 2023. Ontologies in the era of large language models–a perspective. Applied Ontology 18: 399-407. https://doi.org/10.3233/AO-230072.
pandas. 2024. Python Data Analysis Library (Version 3.12). Accessed January 22, 2024. https://pandas.pydata.org/.
Powell, K. R., M. Popescu, S. Lee, D. R. Mehr, and G. L. Alexander. 2023. Examining the use of text messages among multidisciplinary care teams to reduce avoidable hospitalization of nursing home residents with dementia: protocol for a secondary analysis. JMIR Research Protocols 12: e50231. https://doi.org/10.2196/50231.
Sahoo, P., A. K. Singh, S. Saha, V. Jain, S. Mondal, and A. Chadha. 2024. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv preprint arXiv:2402.07927. https://doi.org/10.48550/arXiv.2402.07927.
Wei, J., X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V Le, and D. Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems, edited by S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, vol. 35. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf.
Xie, Z. 2024. Order matters in hallucination: Reasoning order as benchmark and reflexive prompting for large-language-models. arXiv preprint arXiv:2408.05093. https://doi.org/10.48550/arXiv.2408.05093.
Open Access
Peer-Reviewed
Creative Commons
Accepted: 20 January 2026
Published: 13 March 2026
Research reported in this publication was supported by the National Institute on Aging of the National Institutes of Health under Award Number R01AG078281. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Conflicts of Interest:
The authors declare no conflicts of interest.



